在智能制造浪潮席卷全球的今天,傳統制造模式的轉型升級已成為企業生存與發展的關鍵。作為精密制造領域的重要參與者,昊志機電正積極擁抱變革,將目光投向工業互聯網與信息系統集成服務,致力于打造高效、透明、智能的現代化智慧工廠,為自身發展注入新動能,也為行業樹立了轉型升級的典范。
一、 智慧工廠的藍圖:互聯互通與數據驅動
昊志機電所構想的智慧工廠,其核心在于打破信息孤島,實現生產全要素、全流程的深度互聯與數據融合。這并非簡單的設備自動化升級,而是通過部署先進的傳感器、物聯網(IoT)終端、邊緣計算設備等,將數控機床、機器人、AGV小車、檢測儀器乃至倉儲物流系統全面接入網絡,實時采集設備狀態、生產進度、物料消耗、產品質量等海量數據。
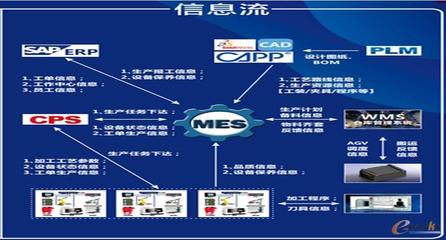
信息系統集成服務在此扮演了“中樞神經”與“智慧大腦”的角色。昊志機電通過構建統一的數據平臺與集成架構,將原本分散的制造執行系統(MES)、企業資源計劃系統(ERP)、產品生命周期管理(PLM)、供應鏈管理(SCM)以及新興的工業互聯網平臺進行深度融合。這種集成實現了從訂單接收、研發設計、生產排程、物料配送、加工裝配到質量檢驗、成品入庫、售后服務的端到端數據貫通與業務協同。
二、 信息系統集成的具體實踐與價值創造
- 生產過程的透明化與精準管控:集成化的MES與設備層數據實時交互,管理者可以遠程、實時地監控每一臺設備的工作狀態、運行效率、故障預警信息。生產進度可視化,能精確追蹤每一個工件在每道工序的流轉情況,實現生產過程的透明化管理。系統可根據實時數據動態優化排產,快速響應插單、急單等需求變化,顯著提升設備綜合利用率(OEE)與訂單交付準時率。
- 質量管理的可追溯與前瞻預防:通過集成質量管理系統(QMS),將檢驗數據與生產批次、設備參數、操作人員等信息自動關聯,建立完整的全生命周期質量檔案。一旦出現質量問題,可迅速追溯至源頭,分析根本原因。更重要的是,利用大數據分析技術,對歷史質量數據與實時工藝參數進行建模分析,能夠預測潛在的質量風險,實現從“事后檢驗”到“事前預防”的轉變,大幅降低廢品率與質量成本。
- 供應鏈的協同優化與敏捷響應:集成化的ERP與SCM系統,實現了內部生產計劃與外部供應商庫存、物流信息的聯動。智慧工廠可根據生產需求,自動生成精準的采購計劃,并通過工業互聯網平臺與核心供應商共享部分生產與需求數據,驅動供應鏈協同備料、準時配送(JIT),減少庫存積壓,提升整個供應鏈的韌性與響應速度。
- 設備運維的預測性與智能化:借助工業互聯網平臺對設備運行數據的持續監測與分析,昊志機電能夠實現預測性維護。系統通過分析振動、溫度、電流等特征參數,智能判斷關鍵部件的健康狀態與性能退化趨勢,在故障發生前提前預警并規劃維護任務,變“被動搶修”為“主動維護”,最大限度減少非計劃停機,保障生產的連續性與穩定性。
- 能源管理的精細化與綠色制造:集成能源管理系統(EMS),對工廠內的水、電、氣等各類能源消耗進行分項、分設備、分時段的精確計量與監控。通過數據分析,識別能耗異常與節能潛力點,優化設備啟停策略和工藝參數,實現能源使用的精細化管理,推動工廠向節能、低碳的綠色制造模式邁進。
三、 面臨的挑戰與未來展望
盡管前景廣闊,但智慧工廠的構建并非一蹴而就。昊志機電在推進過程中也面臨著技術、數據和人才等方面的挑戰:如何確保新舊設備、異構系統的安全可靠集成與數據標準化;如何保障工業數據在采集、傳輸、存儲與應用全過程中的安全與隱私;如何培養與引進既懂制造工藝又精通信息技術與數據分析的復合型人才等。
昊志機電的智慧工廠之路將持續深化。隨著5G、人工智能(AI)、數字孿生等技術的進一步成熟與應用,未來的工廠將更加智能化。數字孿生技術可以在虛擬空間中構建一個與物理工廠完全同步的“數字鏡像”,用于進行工藝仿真、產能預測、方案優化和遠程調試,實現更高效的運營決策。AI算法將在工藝優化、智能排產、缺陷自動檢測、柔性生產調度等方面發揮更大作用,推動工廠向自適應、自決策的更高階段演進。
昊志機電以信息系統集成服務為關鍵抓手,深度融合工業互聯網技術,正穩步推進其智慧工廠的宏偉藍圖。這一轉型不僅是生產工具的升級,更是管理理念、運營模式和商業生態的深刻變革。通過打造數據驅動、敏捷高效、綠色可持續的智能制造新模式,昊志機電不僅強化了自身的核心競爭力,也為中國高端裝備制造業的數字化、網絡化、智能化發展提供了寶貴的實踐參考。在通往工業4.0的道路上,昊志機電的探索與實踐,無疑具有重要的示范意義與引領價值。