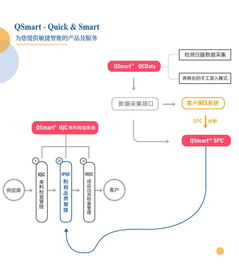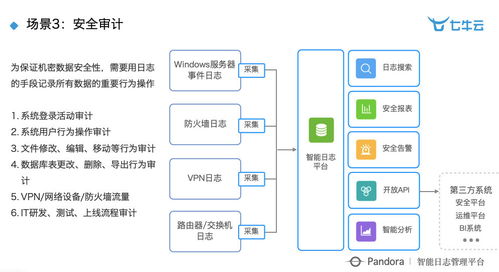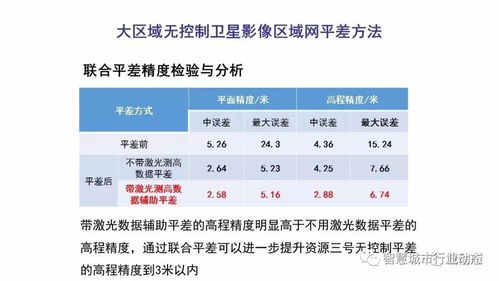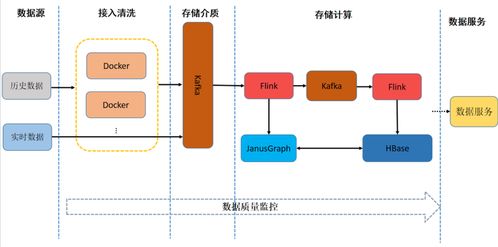
在當今大數據時代,數據處理的規模和實時性成為企業競爭的關鍵要素。友信金服作為金融科技領域的領先企業,面臨著海量用戶數據的挑戰。通過基于Flink構建實時用戶畫像系統,公司成功實現了日處理數據量超過10億條的高效數據處理服務。這一實踐不僅提升了數據處理能力,還為企業精細化運營提供了強有力的數據支持。
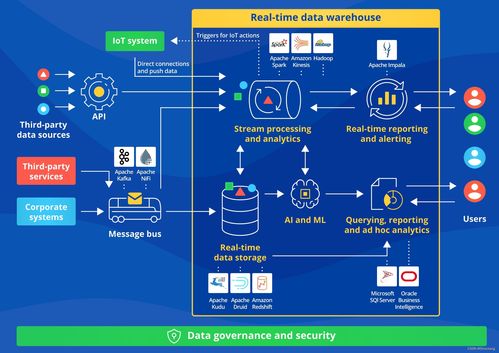
友信金服的用戶畫像系統依托Flink的流處理框架,實現了從數據采集、清洗、聚合到實時分析的全流程自動化。系統的核心優勢在于其高吞吐量和低延遲特性,能夠實時捕捉用戶行為數據,例如瀏覽記錄、交易動態和社交互動,從而動態更新用戶畫像標簽。例如,當用戶完成一筆交易后,系統能在秒級內更新其消費偏好標簽,為后續的個性化推薦和風險控制提供即時依據。
在數據處理服務方面,該系統采用了分布式架構,確保了高可用性和可擴展性。通過Flink的窗口函數和狀態管理功能,系統能夠處理復雜的事件流,例如用戶行為序列的識別和異常檢測。友信金服還結合了機器學習模型,對用戶數據進行智能分析,自動生成多維度的畫像標簽,如信用評分、興趣偏好和風險等級。這不僅提升了數據處理的準確性,還降低了人工干預的成本。
實踐過程中,友信金服面臨了數據一致性和系統性能優化的挑戰。通過引入檢查點機制和容錯處理,系統保證了數據處理的可靠性;通過監控工具實時跟蹤系統指標,如處理延遲和資源利用率,團隊能夠及時調整資源配置,避免瓶頸。結果證明,基于Flink的系統在日處理10億條數據的規模下,仍能保持99.9%的可用性,處理延遲控制在毫秒級別。
友信金服的實時用戶畫像系統不僅展示了Flink在大型數據處理中的強大能力,還為企業帶來了顯著的商業價值。通過實時洞察用戶行為,公司能夠提供更精準的金融服務,增強用戶體驗,同時強化風險管控。這一實踐為其他企業在大數據實時處理領域提供了寶貴的參考,未來可進一步探索與AI技術的深度融合,以應對更復雜的業務場景。